1、在CDH中已经添加了hive
2、配置hive中的hive-site.xml参数 /opt/cloudera/parcels/CDH/lib/hive/conf/hive-site.xml
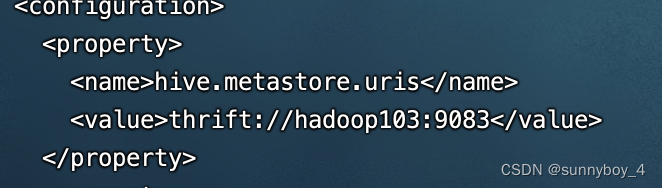
3、配置spark中的hive-site.xml 目录/opt/cloudera/parcels/CDH/lib/spark3/conf/hive-site.xml
<property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.metastore.local</name> <value>false</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://hadoop103:9083</value> </property> 4、修改spark-env.sh,目录/opt/cloudera/parcels/CDH/lib/spark3/conf/
export PYSPARK_PYTHON=/opt/cloudera/anaconda3/bin/python export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark3 5、如果自己在代码中实现这
spark = SparkSession.builder.appName('feat-eng')\ .config("hive.metastore.warehouse.dir",'hdfs://hadoop103:8020/user/hive/warehouse')\ .config("hive.metastore.uris","thrift://hadoop103:9083") \ .enableHiveSupport().getOrCreate() 6、下面就是spark on hive 对接数据
import findspark findspark.init(spark_home='/opt/cloudera/parcels/CDH/lib/spark3',python_path='/opt/cloudera/anaconda3/bin/python') import pyspark from pyspark.context import SparkContext from pyspark.sql import SparkSession from pyspark.sql.functions import * spark = SparkSession.builder.appName('feat-eng')\ .config("hive.metastore.warehouse.dir",'hdfs://hadoop103:8020/user/hive/warehouse')\ .config("hive.metastore.uris","thrift://hadoop103:9083") \ .enableHiveSupport().getOrCreate() '''读取csv的原始数据''' anime_df = spark.read.csv('hdfs://hadoop101:8020/recommandvideo/anime.csv',header=True,inferSchema=True) anime_df.createOrReplaceTempView("temp_anime") '''将数据入库hive''' spark.sql('insert into sparktest.anime select "1",anime_id,name,genre,type,episodes,rating,members from temp_anime') '''读取hive中表的数据''' spark.sql("select * from sparktest.anime").show()